
Unlike an ordinary Merkle tree, immudb tree can produce inclusion and consistency proofs that allow verifying if a particular key is present in the transaction (inclusion proof) and if the later version includes everything in the earlier version, and all new entries come after the entries in the older version (consistency proof).
Inclusion Proof
Inclusion proofs tell us to not simply trust the record, but to verify it by asking for proof.
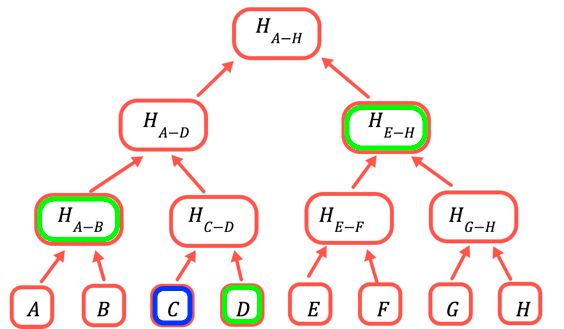
Why create a tree when a hash chain could just work as such? Well, with a tree, it is possible to create proofs-of-inclusion for any data present in the original dataset. When a client gets a record from immudb, it does not simply trust the record. Instead, it requests an inclusion proof from the log and verifies that the proof is valid. This links the content of that record back to a tree head hash. The client then calculates the hash of the record and the chain of hashes up the tree to the tree head hash.
The root hash is the only part that needs to be stored on chain. To prove a certain value, you provide all the hashes that need to be combined with it to obtain the root. For example, to prove C you provide D, H(A-B), and H(E-H).
There are two entities involved in a proof-of-inclusion: the Verifier and the Prover. The Verifier’s responsibility is to check that certain data is part of the original dataset, while the role of the Prover is to prepare the proof and give it to the Verifier.
Inclusion Proof calculation is as follows:
- Verifier sends the Prover the transaction for which it wishes to obtain a proof-of-inclusion.
- The Prover finds this transaction in the Merkle tree and its index, indicating the transaction position in the tree.
- The Prover collects the intermediary hashes, and the transaction root and sends them to the Verifier.
- The Verifier uses the hashes and the transaction data it already has to recalculate the Merkle root and check that the root is equal to the one it originally had.
Consistency proof
Consistency proofs tell us nothing was tampered with.
A consistency proof verifies the consistency between a log at two points in time. It verifies that the later version includes everything in the earlier version, in the same order, and all new entries come after the entries in the older version.
Attack resistance
Merkle trees that accept input datasets with varying length are susceptible to second pre-image attacks. In a second pre-image attack, the goal of the attacker is to find a second input that hashes to the same value of another given input x. In Merkle trees, this corresponds to having two different input datasets giving the same Merkle root. To solve this problem, we prepend a different flag to the data before hashing it, depending on whether the resulting node is a leaf or branch node.
immudb Merkle Tree internals
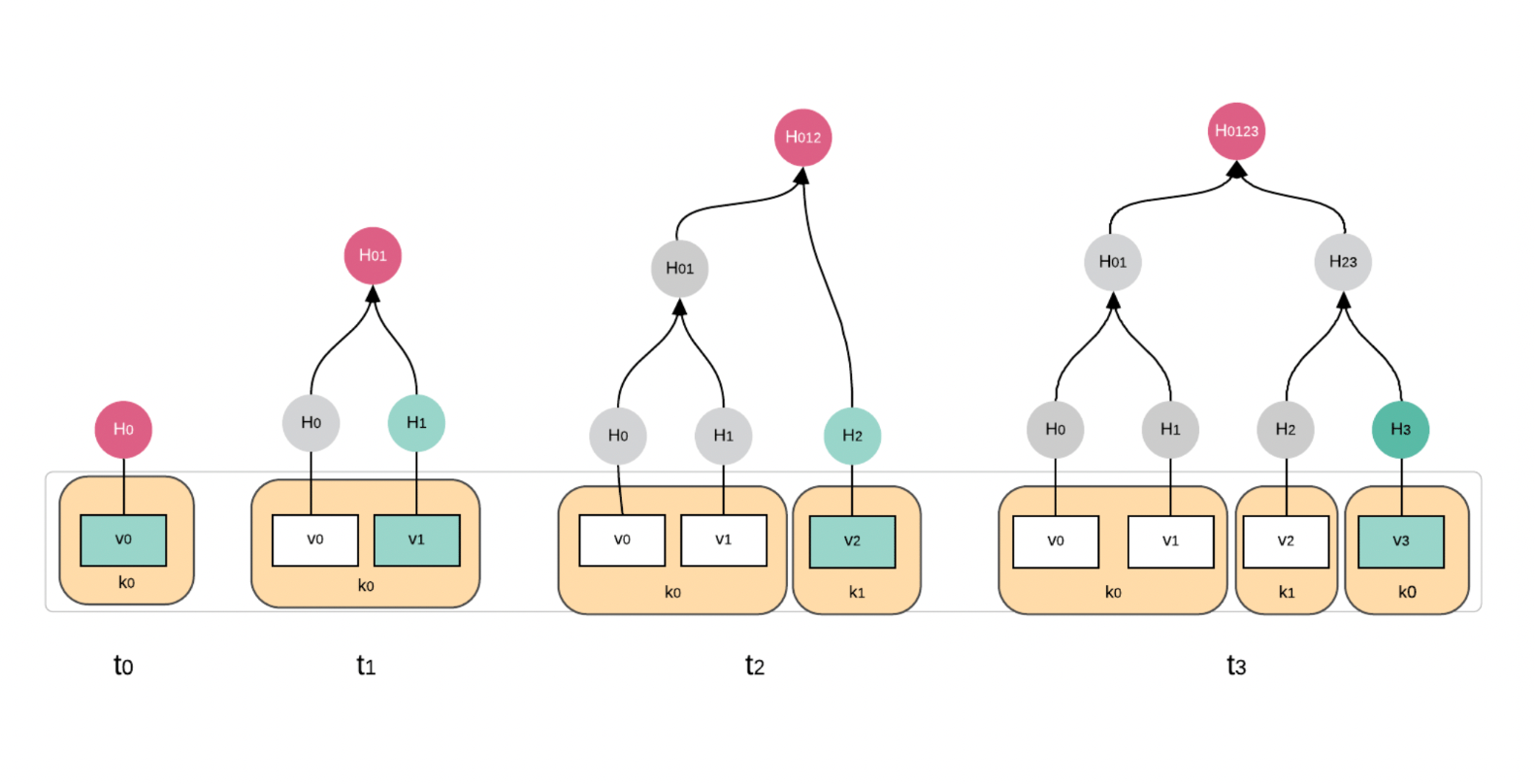
immudb maintains three types of merkle trees:
Main Merkle Tree
Each database has one main Merkle Tree where its inputs are built from transaction hashes/ This tree is persisted in the storage layer. It is also appendable – each new transaction adds one extra leaf node with transaction hash (Alh) and rebuilds the path to the root.
Internal Merkle Tree
Each transaction contains its internal Merkle Tree built from Key-Value-Metadata entries that are part of that single transaction. The root hash of that Merkle Tree (EH) along with transaction metadata and additional linear proof information is used to build the transaction hash that is then input for the main Merkle Tree. This tree is not stored on disk and is recalculated on-demand from data that is building up the transaction.
Linear proof
The additional linear proof for the transaction is a mechanism implemented in immudb that is meant for handling peak transaction writes where the writes are much faster than the main Merkle Tree recalculation. It also forms a linear chain for all transactions since the beginning of the database.
You can read more about the proofs in detail in this excellent documentation from the team here.
The next post in the series is covering the performance of immudb