


General
Indexing is the first thing that comes to mind when we consider a database’s performance. B-tree is an m-way tree that ...
Indexing is the first thing that comes to mind when we consider a database’s performance. B-tree is an m-way tree that self-balances itself. Due to their balanced structure, such trees are frequently used to manage and organise enormous databases and facilitate searches, especially range queries. A B-Tree index speeds up data access because the storage engine doesn’t have to scan the whole table to find the desired data.
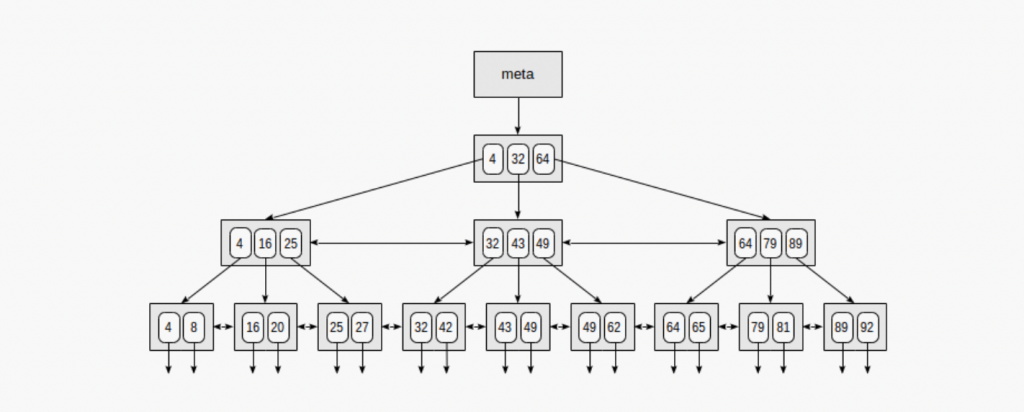
A B-tree:
- keeps keys in sorted order for sequential traversing
- uses a hierarchical index to minimize the number of disk reads
- uses partially full blocks to speed up insertions and deletions
- keeps the index balanced with a recursive algorithm
immudb stores the index in a slightly modified version of a typical B-Tree, called a timed B-tree. A TBtree (a timed B-Tree) stores indexes for records in a database for lookups by the full key, a key range, or a key prefix. They are useful only if the lookup uses a leftmost prefix of the index. The index is useful for the following kinds of queries:
- Match the full key
- Match a leftmost prefix
- Match a range of values
- Match one part exactly and match a range on another part
As the tree’s nodes are sorted, they are helpful for both lookups and ORDER BY queries (finding keys in sorted order). In general, if a B-Tree can help find a row in a particular way, it can help you sort rows by the same criteria. So, the index will be helpful for ORDER BY clauses that match all the types of lookups we just listed. Why is this required you may ask? For SQL support.
SQL support
Our SQL support layer is built on top of the TBtree too. Any SQL schema for a table contains information about the column and datatype.
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
column3 datatype,
....
);immudb stores the schema and records for a table as any other key-value pair in it’s append-only log storage. But to identify the SQL records, a prefix is appended on the key to help identify the schema (or catalog in immudb terminology).
With help of B-Tree for lookups by the full key, a key range, or a key prefix, immudb managed B-Tree support. Also revisions/history for keys are stored in the TBtree, this provides support for fast time-travel for any key by just querying the index.
Note that the values are not stored against the key in the Btree, rather we store the offset of the value in the value-log (explained below) against a key for faster lookups.
Transaction support
Each new transaction in immudb currently creates a snapshot to allow concurrent operations on the database. I’ll write more on how MVCC support works in immudb in an upcoming blog.
The next post in the series covers data persistence of immudb