
Over the last few years many organizations started pilot projects to use blockchains to attain the immutability of their sensitive data. However, the main disadvantages of blockchains (complexity, cost, limits to performance) have in most cases drawn these organizations to simpler, faster and more cost-effective solutions, chiefly among them immutable databases.
Immutable database can only add data, but never delete or alter it. There is no change API and the veracity of the stored data is continuously authenticated thru a cryptographic audit. Quickly a number of solutions emerged.
Some commercial, some open source, and some technologies that build on top of versioning backends, such as git. Immutable databases, such as our very own immudb, are a merger of two main concepts:
Merkle Tree Graphs and cryptographic hashing. Both concepts have been around for decades, but combined they create a new and powerful platform to store data, and have mathematical proof that this data has not been altered in any way.
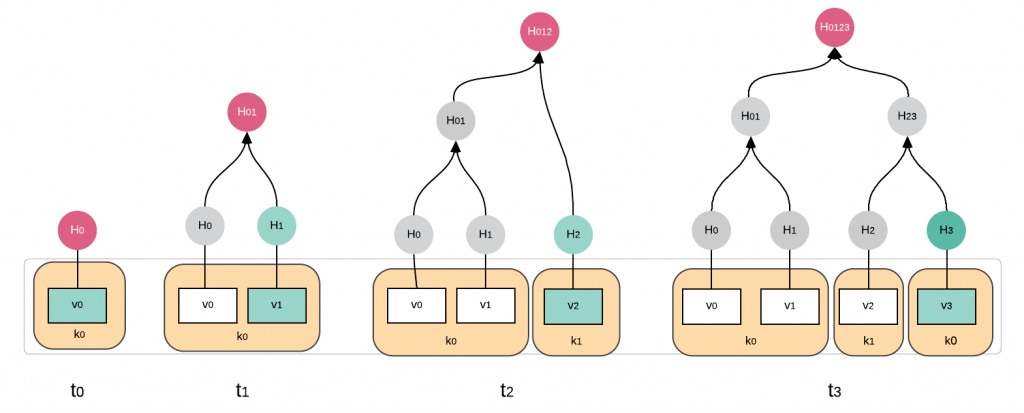
In effect, immutable databases, reverse the concept of Blockchains: whereas in blockchains the distributed ledger authenticates the data, and the client is forced to trust it; in an immutable database ,the client doesn’t trust the database and performs a cryptographic verification of the veracity of the data stored in the database.
Git (DAG) vs Merkle Tree approach
There is also a new breed of versioning databases, which treat data like source files, on Gitlab or github, for example, and use the branching and versioning available to those platforms. The major drawdown of these versioning databases is that the client cannot use a zero trust approach, and instead is asked to trust these versioning platforms to not knowingly or unknowingly spoil the data.
Git forms a directed acyclic graph (DAG) of commits identified by these hashes. Compared to Merkle Tree based data structures, the Git is a graph, not a tree. https://www.geeksforgeeks.org/difference-between-graph-and-tree/
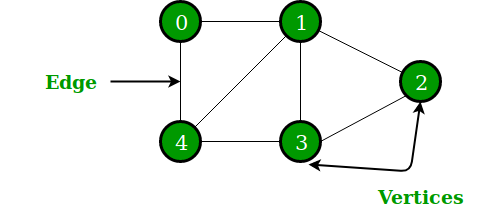
- Nodes in a Merkle tree do not have multiple parents. The DAG does.
- Merkle tree only hashes actual data in its leaf nodes, the Merkle branches after the leaf nodes are hashes of hashes. The Git DAG does not have branches based on hashes of hashes, just nodes with hashes of raw data.
- The Merkle tree starts with the leaf nodes, and proceeds up the tree, constantly halving the number of branches in each iteration. The Git DAG contracts and expands all the time with branching and merging. Because it is a graph and not a tree.
Use cases for immutable databases are principally located where the data change history and the veracity of data are of paramount importance. For example records of financial transactions, government tax records, industrial supply chain events, and many more.
The main offerings in this new category of databases are:
immudb
Immudb, our very own open source immutable database. It’s open source, free, monstrously fast, and has advanced features such as Key/Valey and/or SQL interface. Time travel to see data change history, high availability, scale-out support, a web console and much more.
Amazon QLDB
Amazon QLDB in a commercial offering, similar to our own immudb, however the data is managed by Amazon and it can only be accessed thru the cloud, requiring applications to have access to the Internet. It’s not clear how Amazon stores data in QLDB and the client is responsible to gather the proof information additionally.
Oracle Blockchain Tables
Oracle 21c Blockchain Tables, is a new feature in Oracle’s main database product, which stores data in tables, backed up by Oracle’s internal blockchain. The database must be trusted by the client, and there is no possibility for client authentication of the veracity of the data. Furthermore, tables can still be deleted, and restrictive permissions are required.