
immudb is an open source Immutable Database that supports Cryptographical verification, tamper-resistance, and audit. It has support for both Key-Value and SQL and has high-performance and scalability solutions when compared to its competitors in the market.
Let’s dive deep into how a record is stored on disk by immudb, and the data structures and algorithms used internally.
Basic Building Blocks
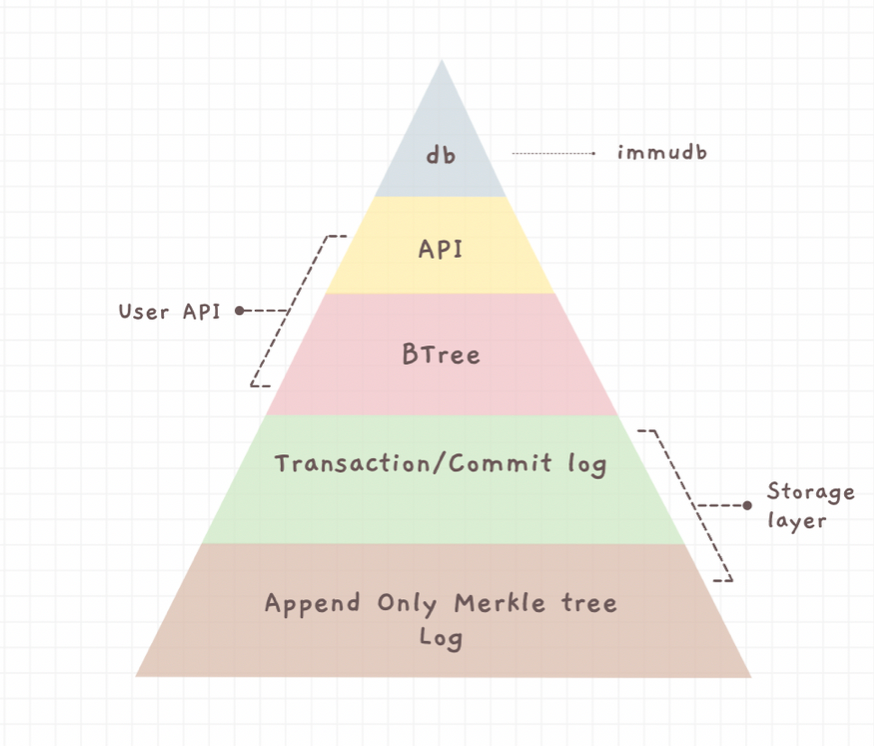
immudb consists of the following data structures:
- Append-only Logs
- Merkle Trees
- Timed B-Tree
Append-Only Logs
Append-only log, also called write-ahead log, is a family of techniques for providing atomicity and durability (two of the ACID properties) in database systems. An append-only log is an auxiliary disk-resident structure used for crash and transaction recovery. Append-only log files keep a record of data changes that occur by writing each change to the end of the file. In doing this, anyone could recover the entire dataset by replaying the append-only log from the beginning to the end. It is also fast, as compared to other database storage systems, because writes are only being appended to a file.
It is a fundamental building block for our immutable database system. Since new updates are layered over the previous ones, developers can time-travel and look into the past versions of a record.
Merkle tree
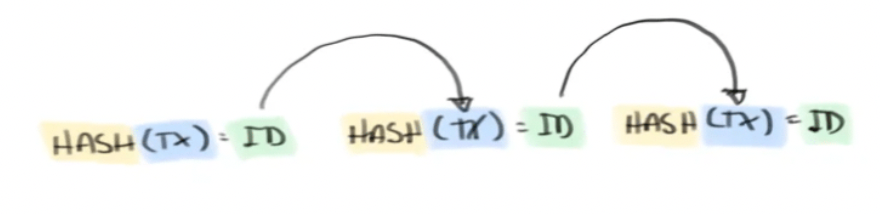
A Merkle tree is an authenticated data structure organized as a tree.
Authenticated means the integrity of the data structure can be efficiently verified using the (Merkle) root of the tree. The dataset cannot be altered without changing the Merkle root. The underlying data structure is organized as a tree, where each parent node is obtained by hashing the data from the child nodes in the layer below.
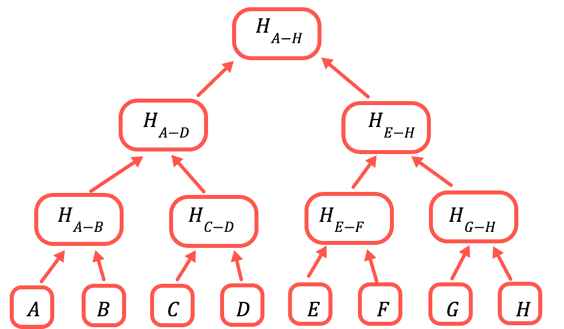
This is how a merkle tree is built:
- Individually hash each element of the original dataset into a leaf node.
- Hash together pairs of leaf nodes and store the resulting value in a parent branch node. The hashing function to obtain a leaf or branch node is different.
- Keep hashing pairs of branch nodes until you get to a single top branch node, the root of the tree.
The next post in this series is about the verification of data in immudb.