
I’ve been working on immudb as a core developer and wanted to answer some questions that the community had in the past. Therefore I have written this blog post series to explain how data is stored in an immutable manner in the database and to understand the data structures (and cryptographic) algorithms used internally.
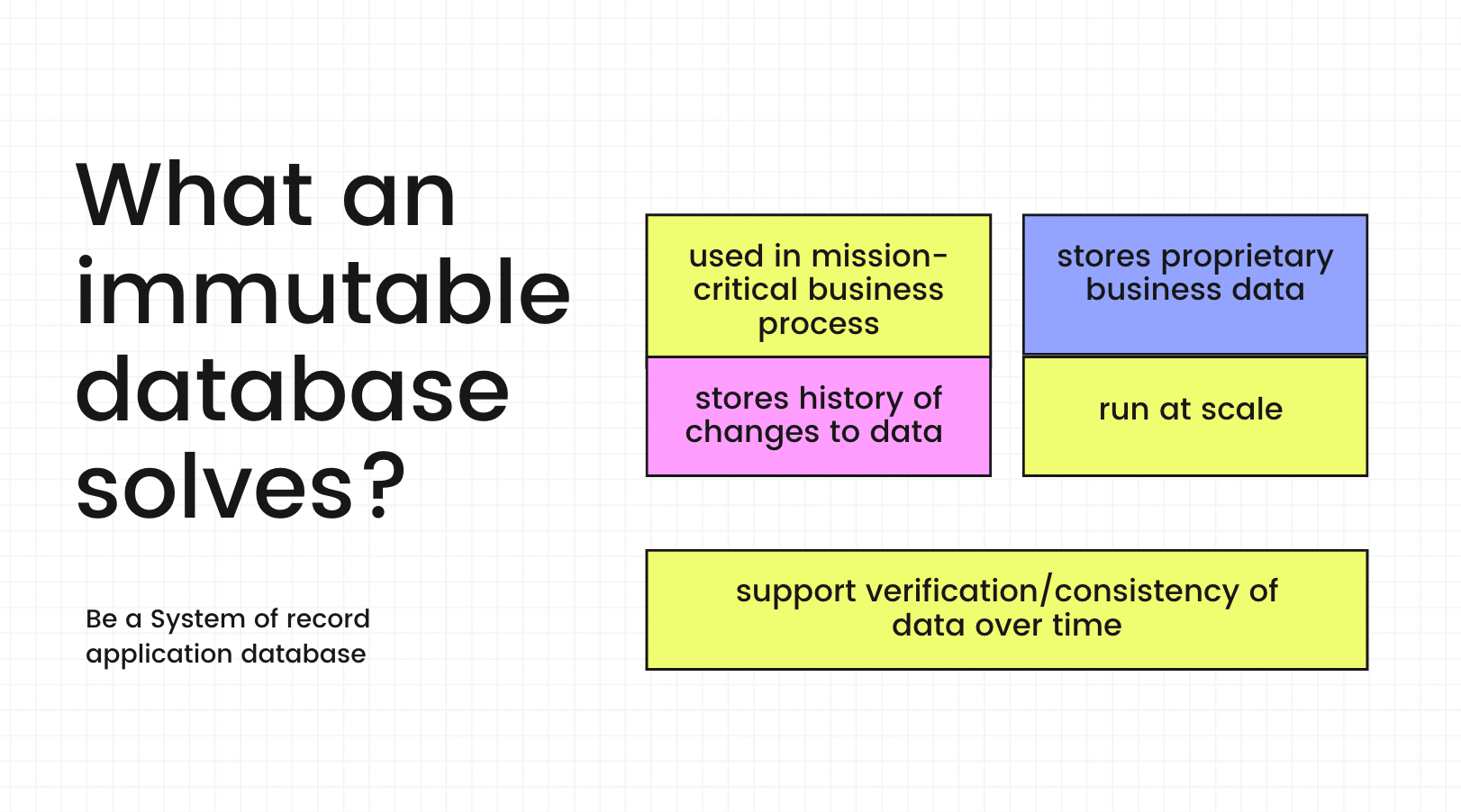
Immutable databases are used for tracking changes in sensitive data, and for auditing purposes. Tamper-evident data means you can cryptographically prove that the data hasn’t been unexpectedly changed. Knowing the provenance, integrity, and sequence in which your data was created means you’ll be able to monitor that the data has not been modified by an unknown user in an unauthorized way, which simplifies regulatory compliance and audit. This is an essential feature within the scope of many activities that collect critical user information and solve issues like insider attack threats, abuses, and patterns on the system through an audit.
A few decades back, storage was expensive, and so was CPU. This is why research in the past on database storage strongly considered storing information efficiently whilst utilizing the least amount of space on disk. Few of the earliest users of databases were finance (and accounting) companies, as it made sense to store their ledger (or accounting) data in a database. Accounting ledgers are immutable. Entries are only appended to the ledger.
Due to disk constraints, many databases added the support to UPDATE a record to utilize the disk efficiently. This is one reason why modern database storage systems are a bit complicated when compared to append-only storage. And this is why they are slow too, as efficient on-disk data management (which requires UPDATES) requires complex data management techniques.
About immudb

immudb is an open-source Immutable Database that supports Cryptographical verification, tamper-resistance, and audit. It has support for both Key-Value and SQL and has high-performance and scalability solutions when compared to its competitors in the market.