


The immudb storage layout consists of the following append-only logs per database:
The immudb storage layout consists of the following append-only logs per database:
- AHT: Append-only Hash Tree. Each database has one main Merkle Tree where its inputs are built from transaction hashes. This tree is persisted in the storage layer. It is also appendable – each new transaction adds one extra leaf node with transaction hash (
Alh) and rebuilds the path to the root. The AHT (Append-only Hash Tree) is a versioned Merkle tree where records are stored as digests left-to-right at the lowest level, following an append-only model. Like a hash chain, this AHT is persistent, with the difference that it supports efficient inclusion and consistency proofs. We can see that the AHT grows always from left to right. This growth property allows us to make efficient claims about the past because we can reconstruct old versions of the tree by pruning specific branches from right to left. - Transaction Log: An append-only log for storing the transaction headers for a transaction. This helps in reading the header information of a transaction easily, as the header size is fixed.
- Commit Log: An append-only log for storing the information about the commits to a database. This log stores the transaction in an ordered way and is used for database recovery as transactions written in this log can be considered fully committed.
- Value Log: An append-only log for storing the actual values of key-value pairs within a transaction. The underlying data structure is again an append-only log. This log is kept separate for faster reads, and because many other data structures internally refer to the values, storing it in a separate log provides ease of access. The B-Tree index and transaction headers do not store the value itself but refer to the offset of the value in the value-log appendable.
- Index Log: An append-only log for storing the index for transactions in a database. Internally, immudb uses a B-Tree to index database records, and provide SQL support, and the index log is the B-Tree storage on disk.
Lifecycle of a transaction in immudb
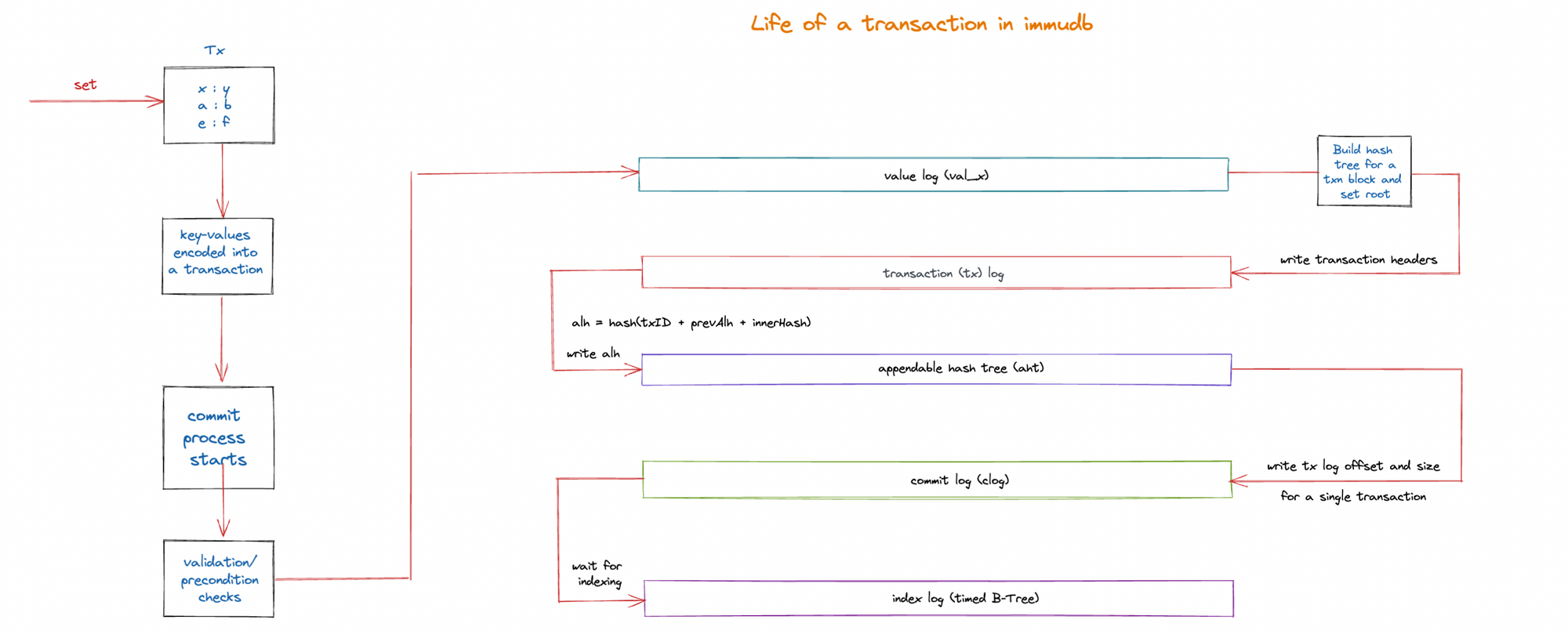
When a transaction is sent to the immudb server, the following events take place:
- Key-Values are encoded in a transaction
- The values are recorded in the value-log appendable, and the offset of those values are stored in the transaction header (transaction log).
- The accumulated linear hash (ALH) is built by chaining the hash of the current transaction + previous transactions ALH + the inner hash of the transaction. This value is then appended to the AHT where the merkle tree is stored and proofs are requested from.
- There could be many concurrent transactions happening on the server, and the commit log stores information of transaction ordering. The Transaction header offset (from the transaction log) and size of the transaction are the only information stored in the commit log.
- Lastly the keys and value offset information is stored in the B-Tree index, and the indexing happens asynchronously and can be recreated on a restart of the database.
References
- https://docs.immudb.io/
- https://github.com/codenotary/immudb-issues/blob/feat/analysis-of-proofs/PROOFS.md#no-validation-of-db-uuid-and-db-name-when-storing-state
You can check out the codebase here, also feel free to raise any doubts you have by creating an issue or joining our Discord: